目的
社内アプリのソースコードを対象としたAI(RAG)を最速(30分以内)で構築します。
- 質問→ベクトル検索→LLM→回答(+シーケンス図作成)
前提条件
- VM(Ubuntu 24.04)
- Docker が動作
- 環境変数
OPENAI_API_KEY を .env に設定
echo OPENAI_API_KEY=sk-… > ~/.env
1. Python 仮想環境&ライブラリ整備
python3 -m venv venv && source venv/bin/activate && pip install chromadb==0.6.3 langchain-chroma==0.2.3 langchain-openai==0.3.14 fastapi uvicorn python-dotenv streamlit requests
2. ベクトルインデックス生成
ソースコードリポジトリをファイル走査して 1,000~1,200文字チャンクに分割し、OpenAI で埋め込み→Chroma に保存。
対象が数千ファイルであれば、実行時間は十数分、コストは
$1.5程度でした。
実行例:
python create_index.py --repo ~/repo1 --persist ~/chroma-data --col repo1
#!/usr/bin/env python3
"""
create_index.py — リポジトリを Chroma インデックス化
"""
import argparse,os,pathlib,shutil,sys
from dotenv import load_dotenv
import openai
from langchain.text_splitter import RecursiveCharacterTextSplitter,Language
from langchain.docstore.document import Document
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import Chroma
p=argparse.ArgumentParser()
p.add_argument('--repo',required=True)
p.add_argument('--persist',default='~/chroma-data')
p.add_argument('--col',default='repo1')
p.add_argument('--chunk',type=int,default=1200)
p.add_argument('--overlap',type=int,default=100)
args=p.parse_args()
ROOT=pathlib.Path(args.repo).expanduser().resolve()
PERSIST=pathlib.Path(args.persist).expanduser().resolve()/args.col
load_dotenv()
openai.api_key=os.getenv('OPENAI_API_KEY') or sys.exit('Missing API key')
EXTS={'.php':Language.PHP,'.ts':Language.TS,'.js':Language.JS,
'.vue':Language.JS,'.twig':Language.HTML,
'.scss':Language.CPP,'.css':Language.CPP}
files=[f for f in ROOT.rglob('*') if f.suffix in EXTS]
docs=[]
for f in files:
try: txt=f.read_text(errors='ignore')
except: continue
docs.append(Document(page_content=txt,metadata={'path':str(f.relative_to(ROOT))}))
splits=[]
for d in docs:
lang=EXTS[pathlib.Path(d.metadata['path']).suffix]
splits+=RecursiveCharacterTextSplitter.from_language(
language=lang,chunk_size=args.chunk,chunk_overlap=args.overlap
).split_documents([d])
if PERSIST.exists(): shutil.rmtree(PERSIST)
emb=OpenAIEmbeddings(model='text-embedding-3-large')
Chroma.from_documents(documents=splits,embedding=emb,
persist_directory=str(PERSIST),collection_name=args.col)
print('Indexed at',PERSIST)
3. 質問応答 API 整備
FastAPI で
/ask(QA)と
/render_mermaid(Mermaid→PNG)を提供。
クエリパラメータでリポジトリ(
repo1/
repo2)とモデル(
gpt-4.1/
gpt-4.1-mini/
gpt-4o-mini/
o4-mini)を切替可能です。
起動例:
uvicorn qa_api:app --host 127.0.0.1 --port 8600 --log-level debug
#!/usr/bin/env python3
"""
qa_api.py — QA(+Mermaid→PNG) API(repo/model切替可)
"""
import pathlib,uuid,subprocess,uvicorn
from fastapi import FastAPI,HTTPException,Query
from fastapi.responses import FileResponse
from pydantic import BaseModel
from dotenv import load_dotenv
from langchain_openai import OpenAIEmbeddings,ChatOpenAI
from langchain_chroma import Chroma
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
PERSIST_BASE=pathlib.Path.home()/'chroma-data'
REPOS=['repo1','repo2']
MODELS=['gpt-4.1','gpt-4.1-mini','gpt-4o-mini','o4-mini']
TMP=pathlib.Path('/tmp/mermaid_pngs');TMP.mkdir(mode=0o777,parents=True,exist_ok=True)
DOCKER_IMG='minlag/mermaid-cli';SCALE='3'
EMB='text-embedding-3-large';TOP_K=8
load_dotenv()
emb=OpenAIEmbeddings(model=EMB)
RETRIEVERS={r:Chroma(persist_directory=str(PERSIST_BASE/r),
collection_name=r,embedding_function=emb
).as_retriever(search_kwargs={'k':TOP_K}) for r in REPOS}
prompt=PromptTemplate(input_variables=['context','question'],template="""
You are a code expert. Context:
{context}
Question:
{question}
1. Answer concisely.
2. If sequence diagram is requested, include a Mermaid sequenceDiagram block.
3. Otherwise, no Mermaid.
""")
app=FastAPI()
class QAReq(BaseModel):question:str
@app.post('/ask')
def ask(req:QAReq,
repo:str=Query('repo1',enum=REPOS),
model:str=Query('gpt-4.1',enum=MODELS)):
retr=RETRIEVERS.get(repo)
if not retr: raise HTTPException(400,'Unknown repo')
if model in ['gpt-4.1','gpt-4.1-mini','o4-mini']:
llm=ChatOpenAI(model_name=model)
else:
llm=ChatOpenAI(model_name=model,temperature=0.0)
chain=RetrievalQA.from_chain_type(llm=llm,chain_type='stuff',
retriever=retr,chain_type_kwargs={'prompt':prompt},
return_source_documents=True)
res=chain(req.question)
return {'answer':res['result'],
'sources':[d.metadata['path'] for d in res['source_documents']]}
class RenderReq(BaseModel):mermaid:str
@app.post('/render_mermaid')
def render(req:RenderReq):
k=uuid.uuid4().hex
m=TMP/f'{k}.mmd';p=TMP/f'{k}.png'
m.write_text(req.mermaid,encoding='utf-8')
try:
subprocess.run(['docker','run','--rm','-v',
f'{TMP.absolute()}:/data',DOCKER_IMG,
'-i',f'/data/{k}.mmd','-o',f'/data/{k}.png',
'-s',SCALE],check=True,stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
except subprocess.CalledProcessError as e:
err=(e.stderr or e.stdout).decode().strip()
raise HTTPException(500,detail=f'Mermaid error: {err}')
return FileResponse(str(p),media_type='image/png')
@app.get('/health')
def health(): return {'status':'ok'}
if __name__=='__main__':
uvicorn.run(app,host='0.0.0.0',port=8600)
4. Web UI 整備
起動例:
streamlit run ui.py --server.port 8501
#!/usr/bin/env python3
"""
ui.py — Streamlit チャット UI(repo/model選択+PNG表示)
"""
import os,re,requests,streamlit as st
from dotenv import load_dotenv
st.set_page_config(page_title='コードアシスタント',layout='wide')
load_dotenv()
API_ASK=os.getenv('API_ASK','http://localhost:8600/ask')
API_RDR=os.getenv('API_RENDER','http://localhost:8600/render_mermaid')
repo=st.sidebar.selectbox('リポジトリ',['repo1','repo2'],index=0)
model=st.sidebar.selectbox('モデル',['gpt-4.1','gpt-4.1-mini','gpt-4o-mini','o4-mini'],index=0)
st.sidebar.markdown(f'ask: `{API_ASK}`')
st.sidebar.markdown(f'render: `{API_RDR}`')
MERMAID_RE=re.compile(r'```mermaid\n(.*?)```',re.S)
st.title('🛠️ コード QA')
if 'chat' not in st.session_state: st.session_state.chat=[]
for r,m in st.session_state.chat: st.chat_message(r).write(m)
q=st.chat_input('質問を入力...')
if q:
st.session_state.chat.append(('user',q));st.chat_message('user').write(q)
with st.spinner('回答中…'):
res=requests.post(f"{API_ASK}?repo={repo}&model={model}",
json={'question':q}).json()
ans,sources=res['answer'],res['sources']
st.session_state.chat.append(('assistant',ans))
with st.chat_message('assistant'):
parts=MERMAID_RE.split(ans)
for i,p in enumerate(parts):
if i%2==0 and p.strip(): st.markdown(p)
if i%2==1:
img=requests.post(API_RDR,json={'mermaid':p}).content
st.image(img,use_container_width=True)
with st.expander('Mermaid ソース'): st.code(p)
if sources:
with st.expander(f'{len(sources)} 件の参照コード'):
for s in sources: st.markdown(f'- `{s}`')
5. Nginx 設定(抜粋)
location /api/ {
proxy_pass http://127.0.0.1:8600/;
}
location / {
proxy_pass http://127.0.0.1:8501;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
}
6. ブラウザで動作確認
ブラウザで / を開き、「ログイン処理の概要やシーケンス図を生成して」など質問すると、回答+シーケンス図が得られます。
今後の予定
自動コードレビューや、エディタ内でのコード補完など。



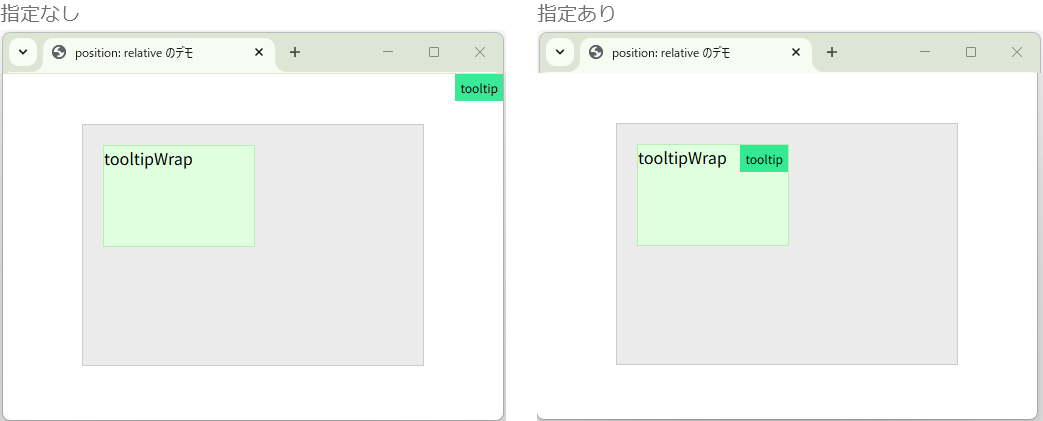 tooltipWrap要素を基準とすることで、ツールチップの位置がtooltipWrap内に収まるようになります。
tooltipWrap要素を基準とすることで、ツールチップの位置がtooltipWrap内に収まるようになります。

